
Sophia: новый способ обучения больших языковых моделей
Команда из Стэнфордского университета создала новый способ предварительного обучения больших языковых моделей — программное обеспечение под названием Sophia, которое работает вдвое быстрее, чем существующие решения.
ChatGPT и другие приложения, использующие большие языковые модели (LLM), становятся все более популярными и привлекают много внимания со стороны СМИ. На текущий момент крупные технологические компании сильно преобладают над малыми на рынке LLM, и все это связано с дороговизной предварительного обучения языковых моделей. Стоимость может составлять от 10 миллионов долларов, а в некоторых случаях данная сумма увеличивается в десятки и сотни раз. Соответственно, для малых организаций или академических групп большие языковые модели на данный момент практически недоступны
Чтобы решить эту проблему, ученые решили улучшить существующие методы оптимизации LLM. Результатом стала разработка под названием Sophia, которая сокращает время предварительного обучения вдвое.
Чтобы оптимизировать предварительную подготовку LLM, разработчики использовали два метода.
Первый из них, известный как оценка кривизны, уже давно известен, но команда из Стэнфордского университета нашла способ сделать этот подход более эффективным. Суть метода заключается в оптимизации количества шагов, которые требуются для предварительного обучения, а также в правильном распределении нагрузки на каждом из этапов.
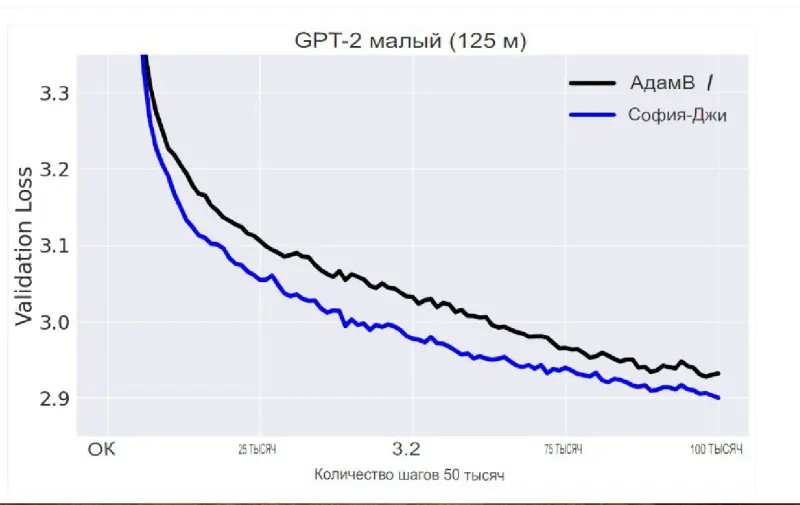
Такой шаг кажется очевидным в контексте рассматриваемого процесса, но, как ни странно, от него отказываются большинство компаний, занимающихся разработкой LLM. Дело в том, что оценка кривизны в техническом плане является дорогостоящей и сложной. Обычно оценка производится на каждом шаге оптимизации. Команда из Стэнфордского университета задалась вопросом: а можно ли сделать процесс более эффективным, уменьшив количество обновлений? Разработав оптимизатор Sophia, ученые добились своей цели — кривизна параметров стала оцениваться примерно каждые 10 шагов.
Второй метод команды, называемый отсечением, решает проблему, возникающую при использовании первого — неточную оценку кривизны. При отсечении устанавливается ограничение или пороговое значение для параметров модели. Если параметры превышают этот порог, их сложность считается неприемлемой, и модель не будет обрабатывать их. Таким образом предотвращаются ошибки или проблемы, возникающие из-за сложности, и улучшается эффективность обучения.
Разработчики использовали Sophia для предварительного обучения относительно небольшой модели LLM, используя те же размеры модели и конфигурацию, которые применялись при создании GPT-2.
В дальнейшем команда планирует разработать более крупную модель LLM с использованием Sophia. Ученые также надеются, что Sophia будет применяться и в других областях машинного обучения, таких как модели компьютерного зрения или мультимодальные модели.
— Гон Лю, аспирант компьютерных наук Стэнфордского университета.
ChatGPT и другие приложения, использующие большие языковые модели (LLM), становятся все более популярными и привлекают много внимания со стороны СМИ. На текущий момент крупные технологические компании сильно преобладают над малыми на рынке LLM, и все это связано с дороговизной предварительного обучения языковых моделей. Стоимость может составлять от 10 миллионов долларов, а в некоторых случаях данная сумма увеличивается в десятки и сотни раз. Соответственно, для малых организаций или академических групп большие языковые модели на данный момент практически недоступны
Чтобы решить эту проблему, ученые решили улучшить существующие методы оптимизации LLM. Результатом стала разработка под названием Sophia, которая сокращает время предварительного обучения вдвое.
Оптимизируя оптимизацию
Чтобы оптимизировать предварительную подготовку LLM, разработчики использовали два метода.
Первый из них, известный как оценка кривизны, уже давно известен, но команда из Стэнфордского университета нашла способ сделать этот подход более эффективным. Суть метода заключается в оптимизации количества шагов, которые требуются для предварительного обучения, а также в правильном распределении нагрузки на каждом из этапов.
Такой шаг кажется очевидным в контексте рассматриваемого процесса, но, как ни странно, от него отказываются большинство компаний, занимающихся разработкой LLM. Дело в том, что оценка кривизны в техническом плане является дорогостоящей и сложной. Обычно оценка производится на каждом шаге оптимизации. Команда из Стэнфордского университета задалась вопросом: а можно ли сделать процесс более эффективным, уменьшив количество обновлений? Разработав оптимизатор Sophia, ученые добились своей цели — кривизна параметров стала оцениваться примерно каждые 10 шагов.
Второй метод команды, называемый отсечением, решает проблему, возникающую при использовании первого — неточную оценку кривизны. При отсечении устанавливается ограничение или пороговое значение для параметров модели. Если параметры превышают этот порог, их сложность считается неприемлемой, и модель не будет обрабатывать их. Таким образом предотвращаются ошибки или проблемы, возникающие из-за сложности, и улучшается эффективность обучения.
Тестирование и масштабирование
Разработчики использовали Sophia для предварительного обучения относительно небольшой модели LLM, используя те же размеры модели и конфигурацию, которые применялись при создании GPT-2.
В дальнейшем команда планирует разработать более крупную модель LLM с использованием Sophia. Ученые также надеются, что Sophia будет применяться и в других областях машинного обучения, таких как модели компьютерного зрения или мультимодальные модели.
Использование Sophia для разработки новой большой языковой модели займет определенное время и достаточно много ресурсов, но так как она является программным обеспечением с открытым исходным кодом, сообщество, безусловно, может брать ее на вооружение
— Гон Лю, аспирант компьютерных наук Стэнфордского университета.
- Алексей Павлов
- arXiv preprint server
Наши новостные каналы
Подписывайтесь и будьте в курсе свежих новостей и важнейших событиях дня.
Рекомендуем для вас

Бомбы с орбиты: почему советская технология, воскрешенная Китаем, встревожила США?
Американцы слишком долго считали свои системы раннего предупреждения лучшими на планете. Теперь......

Битва под Каневом: почему на 350 лет замолчали сокрушительную победу России?
Неудобная победа, предательство и идеология. Мы бы могли вообще не узнать об этом триумфе русского оружия...

С Ноева ковчега сняли запрет: что покажут радары на Арарате?
История, которую больше всего высмеивали ученые, неожиданно становится все более реальной...

Дикий народ чучуна: Кто наводил ужас на коренное население Сибири?
Йети? Люди-изгои? Древнее племя? Пока что вопросов больше, чем ответов...

Мрачный прогноз для США из 1995 года сбылся: в чем великий ученый Саган оказался прав?
Исследователь говорил: все плохо, но еще не все потеряно. Его советы могут реально помочь всему человечеству...

Почему их ДНК не меняется уже 42 000 лет: определен самый древний народ на планете
Три раза предки жителей Океании встречались с исчезнувшими видами людей, и это в корне изменило их гены...

Тайна «косого глаза» Венеры раскрыта: что увидела нейросеть на картинах Боттичелли?
Художник нарисовал пять портретов прекрасной Симонетты Веспуччи. И каждое полотно еще больше подтверждает страшный диагноз...

Новая вселенная внутри звезды: почему Эйнштейн мог ошибаться насчет черных дыр
Больше 20 лет эта гипотеза в буквальном смысле раздирает мир науки. Но, возможно, именно она выведет ученых из тупика сингулярности...

Снегопады в Антарктиде становятся все аномальнее: и ученые, наконец-то, знают почему?
Ученым придется пересмотреть все климатические модели Шестого континента. Кстати, снега там будет выпадать с каждым годом все больше...

Еще одна тайна майя: археологи секрет алтаря в заброшенном городе
Выяснилось, что индейцы долгие столетия продолжали исповедовать, казалось бы, давно забытый древний культ...

Марс под вопросом: что может обнулить иммунитет у космонавтов?
И почему защита организма перестает видеть микробы, выжившие в космосе?...

Кипящая дыра в Йеллоустоуне: почему геологи «проморгали» опасный инцидент?
Геологический детектив: незамеченный взрыв, неожиданный провал и далеко идущие последствия...

43 — проклятый возраст Рюриковичей: почему многие князья не переживали этот роковой рубеж?
Генетики говорят: русская династия слишком поздно поняла, что попала в ловушку «чистой» крови...

Бельгийскую разведку снова взломали: хакеры целый год качали оттуда секретные данные
Эксперты говорят: проникновение было замечено совершенно случайно. И это пугает...

Доказана жизнь на спутнике Юпитера: как же бактериям удалось добраться с Земли на Европу?
За 3,5 миллиарда лет земные бактерии могли долететь до 105 звездных систем. Так что у Европы есть все шансы на «заражение»...

Сначала Стоунхендж был... не каменным: найден прототип легендарного святилища
Доисторическая религия оказалась старше на 500 лет, чем считали ученые. И она играла огромную роль в жизни древних людей...