
Китайцы всего за два месяца создали полноценного конкурента ChatGPT
Из Китая прилетела новость. Местные разработчики выпустили крайне недорогой аналог ChatGPT от OpenAI. Низкая цена и открытый исходный код обрадовали тысячи ученых по всему миру. США, в свою очередь, выразили большую обеспокоенность случившимся.
Эта история началась в конце прошлого года. Китайская лаборатория ИИ DeepSeek удивила мир своей новой разработкой — бесплатной большой языковой моделью DeepSeek-V3. Китайцы представили ее в декабре 2024 года. Созданная всего за два месяца и с бюджетом в 5,58 млн долларов, эта модель оказалась значительно дешевле и быстрее аналогов из Кремниевой долины.
Однако на этом специалисты DeepSeek и не думали останавливаться. Уже через несколько недель они выпустили обновленную версию своего ИИ — DeepSeek-R1. Это случилось меньше недели назад, 20 января 2025 года.
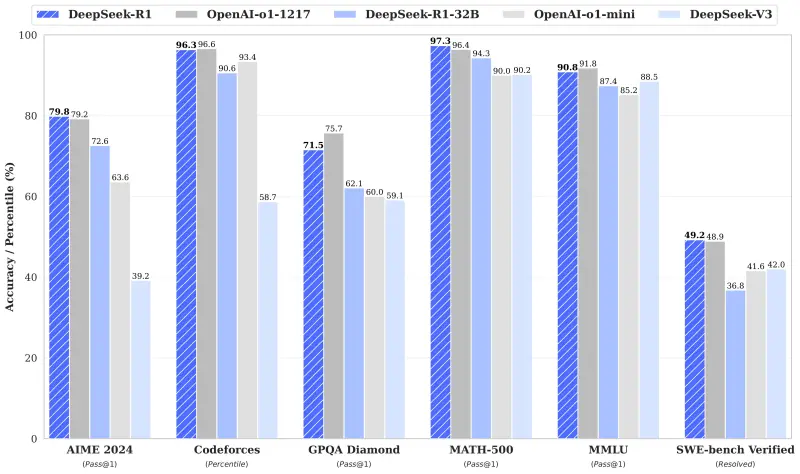
Независимые тесты показали, что DeepSeek-V3 демонстрирует производительность на уровне таких гигантов, как GPT-4 от OpenAI и Claude Sonnet 3.5 от Anthropic, а также превосходит модели вроде Llama 3.1 от Meta и Qwen 2.5 от Alibaba в решении сложных задач, связанных с программированием и математикой.
Успех DeepSeek налицо
R1 также оставил позади последнюю версию ChatGPT o1 в ряде ключевых тестов, что стало настоящим прорывом. Эксперты были поражены не только выдающимися результатами, но и тем фактом, что все это было достигнуто при существенно меньших затратах по сравнению с конкурентами.
Исходный код, который в целом открыт, и использование ограниченного числа GPU подлили еще больше масла в огонь. Теперь многие эксперты в области ИИ и нейросетей начинают склоняться к выводу, что китайские разработки вскоре возьмут верх над американскими.
— Сатья Наделла, гендиректор Microsoft (компания является одним из главных стратегических партнеров OpenAI).
Это заявление Наделла сделал в Давосе на Всемирном экономическом форуме, чем сильно напугал Соединенные Штаты и Западную Европу.
Здесь стоит немного рассказать, как вообще работает ИИ. Он учится на данных, предоставленных человеком, анализируя их и находя скрытые закономерности. Затем на основе выявленных шаблонов нейросеть генерирует ответы на заданные вопросы.
В случае больших языковых моделей основным источником обучения является текст. Так, к примеру, знаменитая GPT-3.5 от OpenAI, вышедшая в 2023 году, прошла обучение на массивном объеме текста размером около 570 ГБ, собранного из разных источников, включая книги, статьи, страницы Википедии и множество других сайтов. Этот гигантский набор данных содержал порядка 300 млрд слов, которые послужили основой для создания мощной языковой модели.
Новые модели, такие как R1 и o1, вышли на новый уровень по сравнению со стандартными большими языковыми моделями благодаря тому, что используют метод цепочки рассуждений. Они способны возвращаться к своим предыдущим выводам, пересматривая и корректируя свои решения. Это помогает гораздо точнее справляться с задачами повышенной сложности.
Стоимость обучения ИИ. Китайцы потратили на все меньше 6 млн долларов
Именно из-за этих способностей ученые и инженеры буквально влюбились в модели-рассуждения и теперь стараются внедрить ИИ в свои проекты.
Но в отличие от закрытой модели o1 в американской ChatGPT китайский DeepSeek предоставляет доступ к своим алгоритмам. Пользователи могут сами просматривать и вносить изменения, при этом обучающие данные все же остаются недоступными.
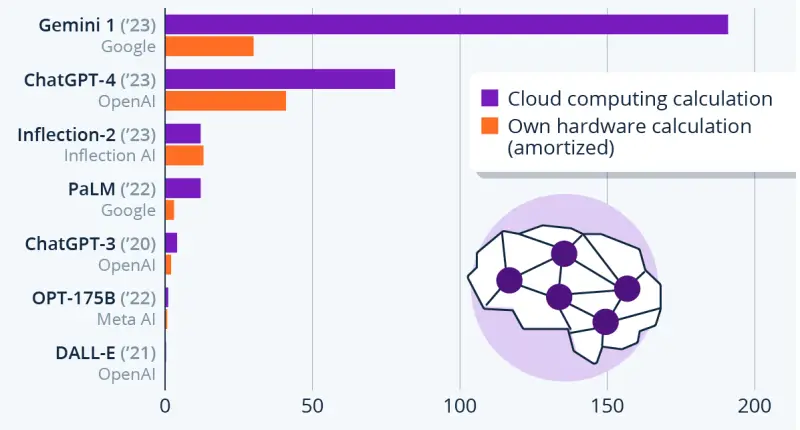
Но главный плюс — стоимость китайской модели в 27 раз ниже цены разработки и обучения американской o1. И это делает продукт от лаборатории DeepSeek еще более конкурентноспособным.
Экономическая эффективность DeepSeek стала одной из главных причин бурных обсуждений этой модели. Бюджет проекта оказался смехотворным по сравнению с огромными суммами, которые конкуренты вложили в разработку своих систем.
К тому же ограничения экспорта технологий из США, препятствующие доступу китайских компаний к передовым вычислительным чипам для ИИ, подстегнули разработчиков R1 искать пути оптимизации алгоритмов, компенсируя недостаток ресурсов. По сообщениям, для обучения ChatGPT потребовались 10 000 мощных графических процессоров Nvidia, тогда как инженеры DeepSeek добились сопоставимых результатов, задействовав лишь 2000 единиц оборудования.

Усовершенствованные алгоритмы DeepSeek позволяют использовать в пять раз меньше оборудования
Таким образом, китайцы кардинально меняют правила игры на рынке искусственного интеллекта. Если раньше считалось, что создание мощной системы ИИ — это привилегия крупных корпораций с многомиллионными бюджетами, то теперь стало понятно — даже небольшие команды и стартапы могут разрабатывать эффективные ИИ-решения, не тратя огромные суммы денег.
Впрочем, американцы пытаются сохранить хорошую мину при плохой игре. Они утверждают, что, на самом деле, никаких успехов у китайцев нет, просто спецы DeepSeek обучили свою модель блестяще проходить тесты. Эксперты из других стран уверены, что китайские разработки и достижения откроют новые горизонты в науке и технологиях. Как будут дальше развиваться события, покажет время.
Настоящий удар по американскому ИИ
Эта история началась в конце прошлого года. Китайская лаборатория ИИ DeepSeek удивила мир своей новой разработкой — бесплатной большой языковой моделью DeepSeek-V3. Китайцы представили ее в декабре 2024 года. Созданная всего за два месяца и с бюджетом в 5,58 млн долларов, эта модель оказалась значительно дешевле и быстрее аналогов из Кремниевой долины.
Однако на этом специалисты DeepSeek и не думали останавливаться. Уже через несколько недель они выпустили обновленную версию своего ИИ — DeepSeek-R1. Это случилось меньше недели назад, 20 января 2025 года.
Независимые тесты показали, что DeepSeek-V3 демонстрирует производительность на уровне таких гигантов, как GPT-4 от OpenAI и Claude Sonnet 3.5 от Anthropic, а также превосходит модели вроде Llama 3.1 от Meta и Qwen 2.5 от Alibaba в решении сложных задач, связанных с программированием и математикой.
Успех DeepSeek налицо
R1 также оставил позади последнюю версию ChatGPT o1 в ряде ключевых тестов, что стало настоящим прорывом. Эксперты были поражены не только выдающимися результатами, но и тем фактом, что все это было достигнуто при существенно меньших затратах по сравнению с конкурентами.
Исходный код, который в целом открыт, и использование ограниченного числа GPU подлили еще больше масла в огонь. Теперь многие эксперты в области ИИ и нейросетей начинают склоняться к выводу, что китайские разработки вскоре возьмут верх над американскими.
Мы должны максимально серьезно отнестись к новостям из Китая
— Сатья Наделла, гендиректор Microsoft (компания является одним из главных стратегических партнеров OpenAI).
Это заявление Наделла сделал в Давосе на Всемирном экономическом форуме, чем сильно напугал Соединенные Штаты и Западную Европу.
Сердито и дешево
Здесь стоит немного рассказать, как вообще работает ИИ. Он учится на данных, предоставленных человеком, анализируя их и находя скрытые закономерности. Затем на основе выявленных шаблонов нейросеть генерирует ответы на заданные вопросы.
В случае больших языковых моделей основным источником обучения является текст. Так, к примеру, знаменитая GPT-3.5 от OpenAI, вышедшая в 2023 году, прошла обучение на массивном объеме текста размером около 570 ГБ, собранного из разных источников, включая книги, статьи, страницы Википедии и множество других сайтов. Этот гигантский набор данных содержал порядка 300 млрд слов, которые послужили основой для создания мощной языковой модели.
Новые модели, такие как R1 и o1, вышли на новый уровень по сравнению со стандартными большими языковыми моделями благодаря тому, что используют метод цепочки рассуждений. Они способны возвращаться к своим предыдущим выводам, пересматривая и корректируя свои решения. Это помогает гораздо точнее справляться с задачами повышенной сложности.
Стоимость обучения ИИ. Китайцы потратили на все меньше 6 млн долларов
Именно из-за этих способностей ученые и инженеры буквально влюбились в модели-рассуждения и теперь стараются внедрить ИИ в свои проекты.
Но в отличие от закрытой модели o1 в американской ChatGPT китайский DeepSeek предоставляет доступ к своим алгоритмам. Пользователи могут сами просматривать и вносить изменения, при этом обучающие данные все же остаются недоступными.
Но главный плюс — стоимость китайской модели в 27 раз ниже цены разработки и обучения американской o1. И это делает продукт от лаборатории DeepSeek еще более конкурентноспособным.
Китай меняет правила
Экономическая эффективность DeepSeek стала одной из главных причин бурных обсуждений этой модели. Бюджет проекта оказался смехотворным по сравнению с огромными суммами, которые конкуренты вложили в разработку своих систем.
К тому же ограничения экспорта технологий из США, препятствующие доступу китайских компаний к передовым вычислительным чипам для ИИ, подстегнули разработчиков R1 искать пути оптимизации алгоритмов, компенсируя недостаток ресурсов. По сообщениям, для обучения ChatGPT потребовались 10 000 мощных графических процессоров Nvidia, тогда как инженеры DeepSeek добились сопоставимых результатов, задействовав лишь 2000 единиц оборудования.
Усовершенствованные алгоритмы DeepSeek позволяют использовать в пять раз меньше оборудования
Таким образом, китайцы кардинально меняют правила игры на рынке искусственного интеллекта. Если раньше считалось, что создание мощной системы ИИ — это привилегия крупных корпораций с многомиллионными бюджетами, то теперь стало понятно — даже небольшие команды и стартапы могут разрабатывать эффективные ИИ-решения, не тратя огромные суммы денег.
Впрочем, американцы пытаются сохранить хорошую мину при плохой игре. Они утверждают, что, на самом деле, никаких успехов у китайцев нет, просто спецы DeepSeek обучили свою модель блестяще проходить тесты. Эксперты из других стран уверены, что китайские разработки и достижения откроют новые горизонты в науке и технологиях. Как будут дальше развиваться события, покажет время.
- Дмитрий Алексеев
- github.com, statista.com, tinhte.vn
Наши новостные каналы
Подписывайтесь и будьте в курсе свежих новостей и важнейших событиях дня.
Рекомендуем для вас

Битва под Каневом: почему на 350 лет замолчали сокрушительную победу России?
Неудобная победа, предательство и идеология. Мы бы могли вообще не узнать об этом триумфе русского оружия...

Бомбы с орбиты: почему советская технология, воскрешенная Китаем, встревожила США?
Американцы слишком долго считали свои системы раннего предупреждения лучшими на планете. Теперь......

С Ноева ковчега сняли запрет: что покажут радары на Арарате?
История, которую больше всего высмеивали ученые, неожиданно становится все более реальной...

Дикий народ чучуна: Кто наводил ужас на коренное население Сибири?
Йети? Люди-изгои? Древнее племя? Пока что вопросов больше, чем ответов...

Почему их ДНК не меняется уже 42 000 лет: определен самый древний народ на планете
Три раза предки жителей Океании встречались с исчезнувшими видами людей, и это в корне изменило их гены...

Тайна «косого глаза» Венеры раскрыта: что увидела нейросеть на картинах Боттичелли?
Художник нарисовал пять портретов прекрасной Симонетты Веспуччи. И каждое полотно еще больше подтверждает страшный диагноз...

Мрачный прогноз для США из 1995 года сбылся: в чем великий ученый Саган оказался прав?
Исследователь говорил: все плохо, но еще не все потеряно. Его советы могут реально помочь всему человечеству...

Новая вселенная внутри звезды: почему Эйнштейн мог ошибаться насчет черных дыр
Больше 20 лет эта гипотеза в буквальном смысле раздирает мир науки. Но, возможно, именно она выведет ученых из тупика сингулярности...

Прорыв в астрономии: найти жизнь в космосе будет гораздо проще
Ученых не пугает даже погрешность в 20%. Зато будут просканированы тысячи планет...

Марс под вопросом: что может обнулить иммунитет у космонавтов?
И почему защита организма перестает видеть микробы, выжившие в космосе?...

43 — проклятый возраст Рюриковичей: почему многие князья не переживали этот роковой рубеж?
Генетики говорят: русская династия слишком поздно поняла, что попала в ловушку «чистой» крови...

Снегопады в Антарктиде становятся все аномальнее: и ученые, наконец-то, знают почему?
Ученым придется пересмотреть все климатические модели Шестого континента. Кстати, снега там будет выпадать с каждым годом все больше...

Тайный Еще одна тайна майя: археологи секрет алтаря в заброшенном городе
Выяснилось, что индейцы долгие столетия продолжали исповедовать, казалось бы, давно забытый древний культ...

Доказана жизнь на спутнике Юпитера: как же бактериям удалось добраться с Земли на Европу?
За 3,5 миллиарда лет земные бактерии могли долететь до 105 звездных систем. Так что у Европы есть все шансы на «заражение»...

Сначала Стоунхендж был... не каменным: найден прототип легендарного святилища
Доисторическая религия оказалась старше на 500 лет, чем считали ученые. И она играла огромную роль в жизни древних людей...

Бельгийскую разведку снова взломали: хакеры целый год качали оттуда секретные данные
Эксперты говорят: проникновение было замечено совершенно случайно. И это пугает...