
Microsoft представил модель искусственного интеллекта, которая понимает содержимое изображений и решает визуальные головоломки
Исследователи из Microsoft представили Kosmos-1, мультимодальную модель, которая, как сообщается, может анализировать изображения на наличие контента, решать визуальные головоломки, выполнять визуальное распознавание текста, проходить визуальные тесты IQ и понимать инструкции на естественном языке. Исследователи считают, что мультимодальный ИИ, который объединяет различные режимы ввода, такие как текст, аудио, изображения и видео, является ключевым шагом к созданию искусственного общего интеллекта (AGI), способного решать общие задачи на уровне человека.
— выдержка из исследовательской статьи.
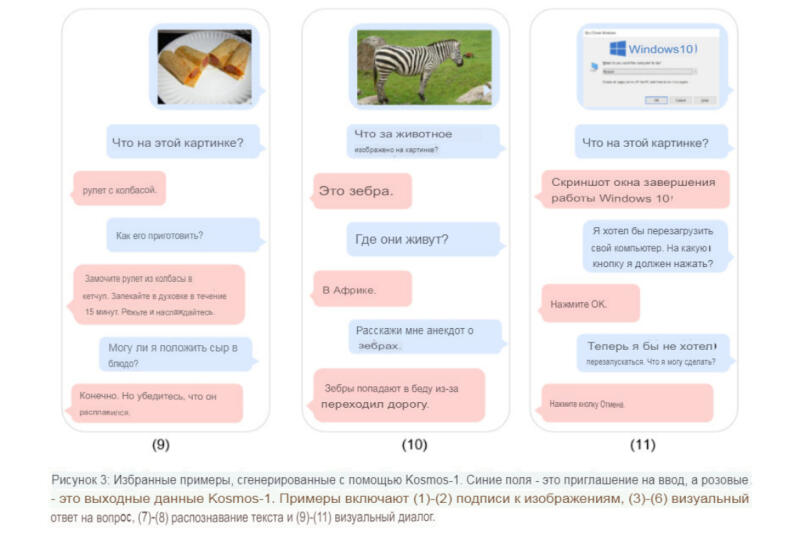
Наглядные примеры из статьи «Kosmos-1» показывают, как модель анализирует изображения и отвечает на вопросы о них, воспринимает текст с изображения, добавляет свои комментарии и проходит визуальный IQ-тест с точностью 22–26 процентов (подробнее об этом ниже).
В то время как СМИ пестрят новостями о больших языковых моделях (LLM), некоторые эксперты выделяют мультимодальный ИИ как потенциальный путь к общему искусственному интеллекту, гипотетической технологии, которая сможет заменить человека в любой интеллектуальной работе.
AGI — это заявленная цель OpenAI, ключевого делового партнера Microsoft в области искусственного интеллекта. Однако в данном случае Kosmos-1 — сольный проект Microsoft, созданный без участия OpenAI. Исследователи называют свое творение «мультимодальной моделью большого языка» (MLLM), так как она включает себя принципы обработки естественного языка, подобные тем, которые использует для понимания текста LLM вроде ChatGPT. Говоря проще: чтобы «Kosmos-1» мог принимать входные изображения, исследователи должны сначала преобразовать изображение в специальную серию токенов (представленных текстом), пригодные для понимания LLM. В статье «Kosmos-1», опубликованной исследователями, это описано более подробно.
— из статьи «Kosmos-1».
Microsoft обучила Kosmos-1, используя данные из Интернета, в том числе выдержки из The Pile (текстовый ресурс на английском языке объемом 800 ГБ) и Common Crawl. После обучения они оценили способности Kosmos-1 в нескольких тестах, включая тест на понимание языка, генерацию языка, классификацию текста без оптического распознавания символов, создание субтитров к изображениям, классификацию изображений и многие другие. По данным Microsoft, во многих из этих тестов Kosmos-1 превзошел современные модели.
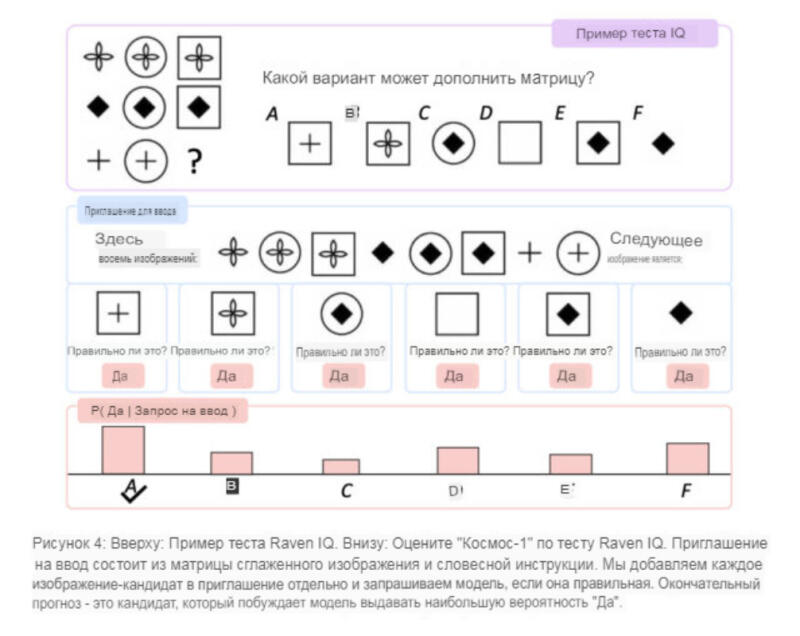
Особый интерес представляет результат Kosmos-1 в тесте Raven's Progressive Reasoning, который измеряет визуальный IQ, представляя последовательность форм и предлагая испытуемому завершить последовательность. Чтобы протестировать «Kosmos-1», исследователи задали ему заполненный тест, с уже заполненными вариантами ответа, и попросили проверить их правильность. Kosmos-1 мог правильно ответить на вопросы из теста Raven только в 22 процентах случаев (в 26 процентах при тонкой настройке). Это ни в коем случае не окончательная победа, и ошибки в методологии могли повлиять на результаты, однако «Kosmos-1» все же превзошел случайный шанс выбора правильного ответа (17 процентов) для теста Raven IQ.
Хотя «Kosmos-1» представляет собой ранние шаги в направлении создания мультимодального ИИ, не сложно представить, что будущие исследования принесут еще более значительные результаты, позволив моделям ИИ воспринимать любые формы медиа и взаимодействовать с ними. В потенциале это значительно расширит возможности помощников на основе искусственного интеллекта. Исследователи говорят, что в будущем они хотели бы увеличить размер модели Kosmos-1, а также интегрировать возможность голосового взаимодействия.
Microsoft заявляет, что планирует сделать Kosmos-1 доступным для разработчиков, хотя на странице GitHub, на которую ссылается газета, после публикации исследования не присутствует код, относящийся напрямую к рассматриваемой модели.
Будучи базовой частью интеллекта, мультимодальное восприятие необходимо для достижения целостности искусственного интеллекта с точки зрения приобретения знаний и привязки к реальному миру. Язык — это не все, что вам нужно, необходимо согласование восприятия с языковыми моделями
— выдержка из исследовательской статьи.
Наглядные примеры из статьи «Kosmos-1» показывают, как модель анализирует изображения и отвечает на вопросы о них, воспринимает текст с изображения, добавляет свои комментарии и проходит визуальный IQ-тест с точностью 22–26 процентов (подробнее об этом ниже).
В то время как СМИ пестрят новостями о больших языковых моделях (LLM), некоторые эксперты выделяют мультимодальный ИИ как потенциальный путь к общему искусственному интеллекту, гипотетической технологии, которая сможет заменить человека в любой интеллектуальной работе.
Что такое искусственный общий интеллект (AGI)
AGI — это заявленная цель OpenAI, ключевого делового партнера Microsoft в области искусственного интеллекта. Однако в данном случае Kosmos-1 — сольный проект Microsoft, созданный без участия OpenAI. Исследователи называют свое творение «мультимодальной моделью большого языка» (MLLM), так как она включает себя принципы обработки естественного языка, подобные тем, которые использует для понимания текста LLM вроде ChatGPT. Говоря проще: чтобы «Kosmos-1» мог принимать входные изображения, исследователи должны сначала преобразовать изображение в специальную серию токенов (представленных текстом), пригодные для понимания LLM. В статье «Kosmos-1», опубликованной исследователями, это описано более подробно.
Для формата ввода мы представляем вводные данные как последовательность, оснащенную специальными токенами. В частности, мы используем и для обозначения начала и конца принцип последовательности. Специальные маркеры указывают на начало и конец встраивания закодированного изображения. Например, «[doc_tag]документ [/doc_tag]» — это текстовый ввод, а «[text_tag] абзац [image] Image.gpg [/image] абзац [/text_tag]» — это чередующийся ввод изображения и текста.
Модуль внедрения используется для кодирования текстовых токенов и других модальностей ввода в векторы. Затем информация отправляется в декодер. Для входных токенов мы используем таблицу поиска, чтобы сопоставить их с необходимой для ответа информацией. Для модальностей непрерывных сигналов (например, изображения и звука) также возможно представить входные данные в виде дискретного кода, а затем рассматривать их как если бы это был иностранный язык
Модуль внедрения используется для кодирования текстовых токенов и других модальностей ввода в векторы. Затем информация отправляется в декодер. Для входных токенов мы используем таблицу поиска, чтобы сопоставить их с необходимой для ответа информацией. Для модальностей непрерывных сигналов (например, изображения и звука) также возможно представить входные данные в виде дискретного кода, а затем рассматривать их как если бы это был иностранный язык
— из статьи «Kosmos-1».
Microsoft обучила Kosmos-1, используя данные из Интернета, в том числе выдержки из The Pile (текстовый ресурс на английском языке объемом 800 ГБ) и Common Crawl. После обучения они оценили способности Kosmos-1 в нескольких тестах, включая тест на понимание языка, генерацию языка, классификацию текста без оптического распознавания символов, создание субтитров к изображениям, классификацию изображений и многие другие. По данным Microsoft, во многих из этих тестов Kosmos-1 превзошел современные модели.
Эффективность прохождения теста на визуальный интеллект
Особый интерес представляет результат Kosmos-1 в тесте Raven's Progressive Reasoning, который измеряет визуальный IQ, представляя последовательность форм и предлагая испытуемому завершить последовательность. Чтобы протестировать «Kosmos-1», исследователи задали ему заполненный тест, с уже заполненными вариантами ответа, и попросили проверить их правильность. Kosmos-1 мог правильно ответить на вопросы из теста Raven только в 22 процентах случаев (в 26 процентах при тонкой настройке). Это ни в коем случае не окончательная победа, и ошибки в методологии могли повлиять на результаты, однако «Kosmos-1» все же превзошел случайный шанс выбора правильного ответа (17 процентов) для теста Raven IQ.
Хотя «Kosmos-1» представляет собой ранние шаги в направлении создания мультимодального ИИ, не сложно представить, что будущие исследования принесут еще более значительные результаты, позволив моделям ИИ воспринимать любые формы медиа и взаимодействовать с ними. В потенциале это значительно расширит возможности помощников на основе искусственного интеллекта. Исследователи говорят, что в будущем они хотели бы увеличить размер модели Kosmos-1, а также интегрировать возможность голосового взаимодействия.
Microsoft заявляет, что планирует сделать Kosmos-1 доступным для разработчиков, хотя на странице GitHub, на которую ссылается газета, после публикации исследования не присутствует код, относящийся напрямую к рассматриваемой модели.
Наши новостные каналы
Подписывайтесь и будьте в курсе свежих новостей и важнейших событиях дня.
Рекомендуем для вас

Бомбы с орбиты: почему советская технология, воскрешенная Китаем, встревожила США?
Американцы слишком долго считали свои системы раннего предупреждения лучшими на планете. Теперь......

С Ноева ковчега сняли запрет: что покажут радары на Арарате?
История, которую больше всего высмеивали ученые, неожиданно становится все более реальной...

Дикий народ чучуна: Кто наводил ужас на коренное население Сибири?
Йети? Люди-изгои? Древнее племя? Пока что вопросов больше, чем ответов...

Мрачный прогноз для США из 1995 года сбылся: в чем великий ученый Саган оказался прав?
Исследователь говорил: все плохо, но еще не все потеряно. Его советы могут реально помочь всему человечеству...

Почему их ДНК не меняется уже 42 000 лет: определен самый древний народ на планете
Три раза предки жителей Океании встречались с исчезнувшими видами людей, и это в корне изменило их гены...

Тайна «косого глаза» Венеры раскрыта: что увидела нейросеть на картинах Боттичелли?
Художник нарисовал пять портретов прекрасной Симонетты Веспуччи. И каждое полотно еще больше подтверждает страшный диагноз...

Васюганские топи: что скрывает самое большое болото на планете?
И почему его называют вечно молодым? И кто прятался в самом сердце мрачных болот?...

Кипящая дыра в Йеллоустоуне: почему геологи «проморгали» опасный инцидент?
Геологический детектив: незамеченный взрыв, неожиданный провал и далеко идущие последствия...

Новая вселенная внутри звезды: почему Эйнштейн мог ошибаться насчет черных дыр
Больше 20 лет эта гипотеза в буквальном смысле раздирает мир науки. Но, возможно, именно она выведет ученых из тупика сингулярности...

Еще одна тайна майя: археологи секрет алтаря в заброшенном городе
Выяснилось, что индейцы долгие столетия продолжали исповедовать, казалось бы, давно забытый древний культ...

Снегопады в Антарктиде становятся все аномальнее: и ученые, наконец-то, знают почему?
Ученым придется пересмотреть все климатические модели Шестого континента. Кстати, снега там будет выпадать с каждым годом все больше...

Марс под вопросом: что может обнулить иммунитет у космонавтов?
И почему защита организма перестает видеть микробы, выжившие в космосе?...

43 — проклятый возраст Рюриковичей: почему многие князья не переживали этот роковой рубеж?
Генетики говорят: русская династия слишком поздно поняла, что попала в ловушку «чистой» крови...

Бельгийскую разведку снова взломали: хакеры целый год качали оттуда секретные данные
Эксперты говорят: проникновение было замечено совершенно случайно. И это пугает...

Доказана жизнь на спутнике Юпитера: как же бактериям удалось добраться с Земли на Европу?
За 3,5 миллиарда лет земные бактерии могли долететь до 105 звездных систем. Так что у Европы есть все шансы на «заражение»...

Сначала Стоунхендж был... не каменным: найден прототип легендарного святилища
Доисторическая религия оказалась старше на 500 лет, чем считали ученые. И она играла огромную роль в жизни древних людей...